
如何基于 Hindsight + Hermes-Agent 构建强大的 AI Agent 记忆与检索系统
从短期记忆到长期学习的全链路记忆架构实战
你有没有想过,为什么你的 AI 助手每次对话都像在"失忆"?
昨天你花了半小时教它你的代码风格偏好,今天它全忘了。上周它帮你分析的项目风险,这周要用还得重新说一遍。这不是个例,是当前绝大多数 AI Agent 的真实写照。
问题出在哪里?它们只有"对话历史",没有"记忆系统"。
本文介绍两个互补的开源项目:Hindsight(仿生记忆引擎)和 Hermes-Agent(自进化 Agent 框架)。两者结合,能让 Agent 从经验中学习,而不是每次都从零开始。
一、AI Agent 记忆系统的现状与挑战
当前主流方案的困境
目前 AI Agent 的记忆方案大致分为三类,但每一类都有明显短板。
上下文窗口扩展是最直觉的做法——把更多历史对话塞进 prompt。但随着对话变长,成本线性增长,关键信息还会被稀释。一个 200K token 的窗口听起来很大,但在高频交互场景下几天就填满了。
RAG(检索增强生成) 是目前的主流选择。将对话转为向量存入数据库,需要时按语义相似度检索。但它严重依赖向量匹配质量,对于需要推理和关联的复杂查询,单纯的语义相似度远远不够。
知识图谱能表达实体关系,但构建和维护成本极高。手动标注不现实,自动抽取的质量又参差不齐。
"记住"不等于"学会"
这里有个关键的认知差异:记忆不等于学习。
一个真正的记忆系统需要具备四个能力:
能力说明传统方案支持度 存取存储和检索信息✅ 基本满足 推理从已有信息推导新结论❌ 大部分缺失 反思回顾经历,发现模式❌ 几乎没有 遗忘淘汰过时信息⚠️ 粗暴截断大多数 Agent 只停留在"存取"层面。它们能记住你说了什么,但无法理解你为什么这么说,更不能从中提炼出可复用的知识。
理想的 Agent 记忆系统应该像人脑一样:既有短期工作记忆处理当前任务,又有长期记忆沉淀经验,还能通过反思形成深层认知。
Hindsight + Hermes-Agent 的组合,正是为这个目标设计的。
二、Hindsight:让 Agent 真正学会的记忆引擎
Hindsight 由 Vectorize.io 团队开源,目前在 GitHub 上已获得超过 10,500 个 Star,采用 MIT 协议。它的核心理念只有一句话:让 Agent 学习,而不仅仅是记住。
2.1 仿生记忆模型:World / Experiences / Mental Models
Hindsight 的设计灵感来自人类记忆系统。它将 Agent 的记忆分为三个层次:
World(世界知识)——关于世界的客观事实。就像你知道"火是热的",这类记忆是静态的、可共享的。在 Agent 场景下,它存储项目的技术栈信息、团队的开发规范等事实性知识。
Experiences(经历)——Agent 自身的交互经历。类比于"我被烫过",这类记忆是个人化的、带时间戳的。它记录 Agent 在特定场景下的行为和结果,比如"用户偏好用 TypeScript 而非 JavaScript 编写工具函数"。
Mental Models(心智模型)——通过反思形成的深层认知。这相当于"我知道不该碰热的东西"。它不是原始记忆的简单堆叠,而是跨越多次经历的抽象和合成。
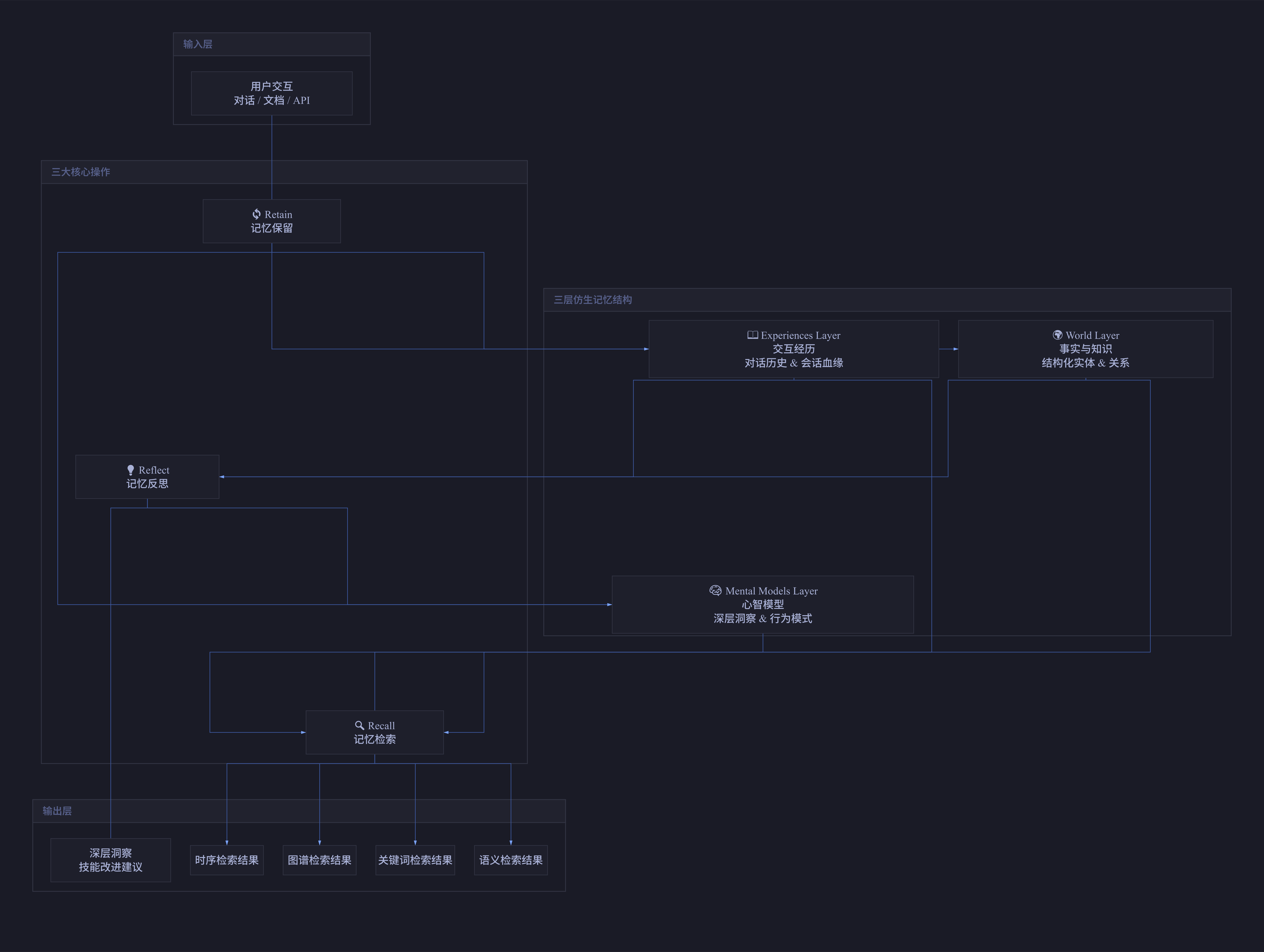
图1:Hindsight 三层仿生记忆模型,展示 World/Experiences/Mental Models 的层次关系与 Retain/Recall/Reflect 操作流转
为什么这种分层比单纯的向量搜索更有效?因为真实场景中的信息需求往往是多层次的。有时你需要精确的事实(World),有时需要相关的经验(Experiences),有时需要综合判断(Mental Models)。单一检索策略无法同时满足这些需求。
2.2 三大核心操作:Retain / Recall / Reflect
Hindsight 围绕三个核心操作构建了完整的记忆生命周期。
Retain(保留):将信息存入记忆系统。它不是简单的文本存储——Hindsight 使用 LLM 自动提取关键事实、时间数据、实体和关系,然后将这些结构化信息转换为规范实体、时间序列和搜索索引。
from hindsight import HindsightClient
client = HindsightClient(api_key="your-api-key")
# Retain:存储信息,自动提取实体和关系
client.retain(
content="用户偏好使用 TypeScript 编写工具函数,"
"并遵循函数式编程风格",
context="代码风格讨论",
tags=["preference", "coding-style"]
)Recall(回忆):从记忆中检索信息。Hindsight 采用四路并行检索策略:
- 语义搜索:基于向量相似度的模糊匹配
- 关键词搜索:基于 BM25 算法的精确匹配
- 图谱检索:沿实体关系和因果链路遍历
- 时序过滤:按时间范围缩小结果集
四路结果汇总后,使用 Reciprocal Rank Fusion(RRF,倒数排名融合) 进行合并,再用 Cross-Encoder 精排,最终根据 token 预算裁剪输出。
# Recall:多策略并行检索
results = client.recall(
query="用户对代码风格有什么偏好?",
budget="mid", # 检索预算:low / mid / high
max_tokens=4096, # 最大返回 token 数
tags=["preference"], # 按标签过滤
types=["world", "experiences"] # 指定记忆类型
)
print(results.summary)Reflect(反思):跨记忆的深层合成。这是让 Agent 从"记住"跨越到"学会"的关键操作。Reflect 调用 LLM 对多条相关记忆进行综合分析,生成新的洞察。
# Reflect:跨记忆的深度分析与洞察
insight = client.reflect(
query="基于过去一周的交互,"
"总结用户的核心技术偏好和沟通模式",
budget="high"
)
print(insight.synthesis)
# 输出示例:
# "用户具有强烈的技术偏好:偏好 TypeScript + 函数式风格,
# 沟通中倾向于简洁的代码示例而非长篇解释..."在 LongMemEval(对话 AI 记忆系统评测基准)上,Hindsight 达到了 SOTA(当前最优)性能,并由 Virginia Tech Sanghani Center 和华盛顿邮报独立复现验证。
三、Hermes-Agent:内置学习循环的自进化 Agent
Hermes-Agent 由 NousResearch 开源,拥有超过 11 万 Star,同样是 MIT 协议。它的定位很明确:一个能自我进化的 AI Agent。
3.1 闭环学习架构:从经验中创建技能,在使用中改进
Hermes 最独特的设计是它的闭环学习系统。这个循环包含四个阶段:
记忆积累:Agent 在交互中持续积累经验和知识。这个过程是自动的,每次对话中的重要信息都会被提取和存储。
技能创建:完成复杂任务后,Agent 会自主将解决方案提炼为可复用的"技能"。这些技能遵循 agentskills.io 开放标准,目前已有 100 多个内置技能。
使用改进:技能在实际使用中不断被验证和优化。如果某个技能效果不佳,Agent 会自动调整其参数或流程。
知识持久化:经过验证的知识被固化,形成 Agent 的长期知识储备。
在记忆存储层面,Hermes 内置了两个精简但高效的记忆文件:
- MEMORY.md(2200 字符上限):Agent 的个人笔记,存储环境事实、约定和学到的经验
- USER.md(1375 字符上限):用户画像,记录偏好、沟通风格和期望
这两个文件在系统启动时作为冻结快照注入 prompt,确保 Agent 始终能访问最关键的信息。
Hermes 通过 SQLite + FTS5 实现了会话级搜索。它能全文本搜索历史对话,并使用 Gemini Flash 生成摘要,实现跨会话的信息回顾。
3.2 MemoryProvider 插件体系:可扩展的记忆后端
Hermes 的记忆系统采用插件架构设计,核心是 MemoryProvider 抽象基类。
图2:Hermes MemoryProvider 插件架构,展示基类生命周期钩子与 Hindsight 等外部提供者的关系
插件的生命周期钩子覆盖了完整的记忆交互流程:
钩子方法触发时机作用initialize()Agent 启动连接后端、创建资源、预热
system_prompt_block()系统提示构建注入静态提示文本
prefetch(query)每轮对话前后台预取相关记忆
sync_turn(user, asst)每轮对话后异步写入对话数据
get_tool_schemas()工具注册暴露工具给模型
handle_tool_call()工具调用分发并执行工具请求
shutdown()Agent 退出清理资源
还有可选钩子:on_turn_start(带上下文的轮次回调)、on_session_end(会话结束提取)、on_pre_compress(压缩前提取)等,提供了丰富的扩展点。
Hermes 官方提供了 8 个记忆提供者:Honcho、OpenViking、Mem0、Hindsight、Holographic、RetainDB、ByteRover 和 Supermemory。每个提供者各有特色,Hindsight 的强项在于知识图谱和反思合成。
有一条重要规则:同一时间只能激活一个外部记忆提供者,但内置记忆(MEMORY.md/USER.md)始终活跃。这种设计确保了基础记忆能力的稳定性,同时允许通过插件扩展高级记忆能力。
四、深度融合:Hindsight × Hermes-Agent 的架构设计
Hindsight 已经是 Hermes-Agent 的官方内置记忆提供者插件,代码位于 plugins/memory/hindsight/ 目录。这意味着两者的集成不是第三方 hack,而是经过官方验证的一等公民方案。
4.1 分层记忆架构:短期 + 长期的协同设计
结合后的系统形成了清晰的分层记忆架构:
L1 内置记忆(MEMORY.md + USER.md)——高频关键事实的快速通道。
这部分容量有限(合计约 3500 字符),但访问速度最快。它存储的是 Agent 日常最需要的信息:用户的姓名和偏好、项目的核心约定、最近的关键决策。
L2 Hindsight 长期记忆——无限扩展的深度记忆层。
这里是 Hindsight 的舞台。World/Experiences/Mental Models 三层结构提供了无限的存储容量和多策略检索能力。所有不适合放入 L1 的详细信息、历史交互记录、反思洞察,都存储在这里。
两层记忆的协同方式:
- 自动预取(prefetch):每轮对话前,Hindsight 插件在后台自动检索相关记忆,注入到上下文中
- 工具调用:Agent 可以主动调用
hindsight_recall和hindsight_reflect工具获取更详细的信息 - 异步写入:对话内容通过
sync_turn自动传递给 Hindsight,由后台异步处理 retain,不阻塞响应
4.2 数据流分析:从对话到记忆的完整生命周期
理解数据流是掌握这套系统的关键。下面看三条核心路径。

图3:从用户输入到记忆写入的完整数据流,展示写入、读取、反思三条核心路径
写入路径:
用户发送消息 → Agent 生成回复 → sync_turn(user_msg, assistant_msg) 触发 → Hindsight 异步执行 retain → LLM 提取实体和关系 → 结构化存储到三层记忆
关键点在于"异步"。retain 操作涉及 LLM 调用和实体提取,耗时较长。Hermes 通过异步处理确保不会因为记忆写入而延迟 Agent 响应。
读取路径:
用户发送查询 → prefetch(query) 在后台启动 → Hindsight 执行 recall(四路并行检索 + RRF 重排)→ 结果注入到上下文 → Agent 结合预取结果和自身推理生成回复
prefetch 同样是后台非阻塞的。如果检索未完成,Agent 会基于已有信息继续响应,不会等待。
反思路径:
定期或在特定场景下触发 reflect → LLM 分析多条相关记忆 → 生成 Mental Models(深层洞察)→ 洞察可用于更新 MEMORY.md 或创建新技能
会话血缘通过 session/parent 标签追踪。每个会话都标记了来源,Agent 能追溯某个结论是从哪次对话中得出的。
4.3 三种部署模式详解
Hindsight 提供三种部署模式,适配不同的使用场景和技术要求。
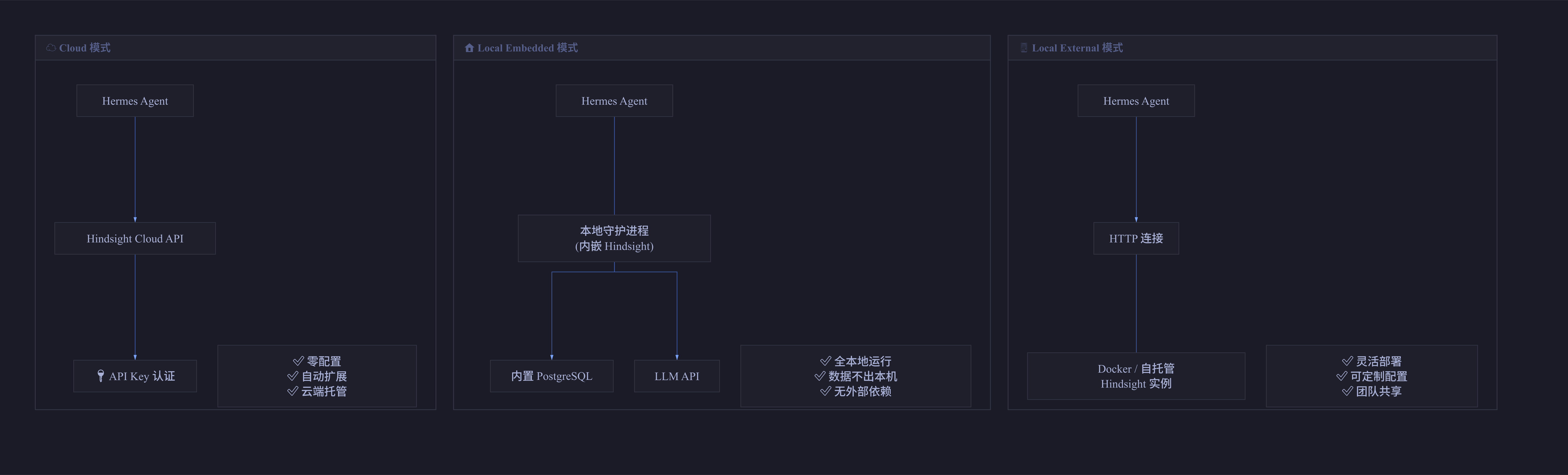
图4:Cloud / Local Embedded / Local External 三种部署模式的架构对比
Cloud 模式:连接 Hindsight Cloud API。
这是最简单的方案,只需一个 API Key 即可使用。适合快速验证和个人项目。数据存储在 Hindsight 的云端,无需本地部署任何额外服务。
Local Embedded 模式:本地嵌入式部署。
这是性价比最高的方案。Hermes 会自动启动一个本地 Hindsight 守护进程,内置 PostgreSQL 数据库,零额外配置。你只需要一个 LLM API Key(用于实体提取和反思),不需要安装 Docker 或配置数据库。
Local External 模式:Docker 或自托管部署。
适用于企业级场景。你可以独立部署和管理 Hindsight 实例,通过 HTTP 连接。这提供了完全的数据控制权,适合对数据隐私有严格要求的场景。
三种模式的核心区别:
维度CloudLocal EmbeddedLocal External 上手难度⭐ 最简单⭐⭐ 简单⭐⭐⭐ 需运维 数据位置Hindsight 云端本地文件系统自托管服务器 额外依赖无LLM API KeyDocker + 数据库 适用场景快速验证个人/小团队企业级部署 扩展性弹性单机可集群五、实战:5 分钟为 Hermes Agent 配置 Hindsight 记忆
理论部分说完了,接下来动手。从零开始配置 Hindsight 记忆。
5.1 快速上手:Cloud 模式
第一步:安装 Hermes Agent
# 使用 pip 安装 Hermes Agent
pip install hermes-agent
# 验证安装
hermes --version第二步:配置 Hindsight 记忆提供者
# 启动记忆系统配置向导
hermes memory setup
# 向导会依次询问:
# 1. 选择记忆提供者 → 选择 "Hindsight"
# 2. 选择部署模式 → 选择 "Cloud"
# 3. 输入 Hindsight API Key
# 4. 配置记忆模式 → 推荐选择 "hybrid"(默认)第三步:验证配置
# 启动 Hermes Agent
hermes chat
# 在对话中测试记忆功能
> 请记住:我的项目使用 React 19 + TypeScript 5.7,代码风格遵循 Airbnb 规范
> 我之前告诉过你我的技术栈是什么吗?
# Agent 应该能正确回忆起 React 19 + TypeScript 5.7配置完成后,Hermes 会在每轮对话前自动预取相关记忆,在对话后自动保存新的记忆。你也可以随时通过 hindsight_recall 工具主动查询。
5.2 进阶配置:Local Embedded 模式
如果你不想把数据发送到云端,Local Embedded 模式是最佳选择。
# 安装时包含 Hindsight 本地依赖
pip install hermes-agent[hindsight]
# 启动配置向导
hermes memory setup
# 选择 "Hindsight" → "Local Embedded"
# 配置 LLM Provider(用于实体提取)Hermes 会自动在本地启动 Hindsight 守护进程(内置 PostgreSQL),无需手动安装任何数据库。
# 配置文件通常位于 ~/.hermes/memory_providers/hindsight.yaml
provider: hindsight
mode: local_embedded
# LLM Provider 配置(用于实体提取和反思)
llm:
provider: openai # 支持 openai / anthropic / ollama 等
model: gpt-4o-mini # 推荐:性价比高,速度快
api_key: ${OPENAI_API_KEY}
# 记忆检索配置
recall:
budget: mid # low / mid / high
prefetch_method: recall # recall(原始事实)或 reflect(LLM 合成)
max_tokens: 4096
# 记忆写入配置
retain:
every_n_turns: 1 # 每隔 N 轮对话自动 retain 一次
# 记忆模式
memory_mode: hybrid # hybrid / context / tools查看守护进程状态和日志:
# 检查守护进程状态
hermes memory status
# 查看实时日志
hermes memory logs --follow
# 打开 Hindsight Web UI 查看记忆状态(如果可用)
hermes memory ui5.3 最佳实践与调优建议
配置完成后,以下调优技巧能帮你获得更好的效果。
memory_mode 选择策略:
# 三种记忆模式的配置代码
# hybrid(默认推荐):自动注入 + 工具可用
# Agent 既能在上下文中看到预取的记忆,
# 也能主动调用 hindsight_recall/reflector 工具
memory_mode: hybrid
# context:仅自动注入,不暴露工具
# 适合简单场景,减少 token 消耗
# Agent 只能看到 prefetch 注入的记忆
memory_mode: context
# tools:仅工具,无自动注入
# 适合需要精细控制记忆访问的场景
# Agent 必须主动调用工具才能获取记忆
memory_mode: toolsrecall_prefetch_method 的场景选择:
recall:返回原始事实和经历,适合需要精确信息的场景reflect:返回 LLM 合成的洞察,适合需要综合判断的场景
一般建议使用 recall,仅在需要高层总结时切换到 reflect。
bank_id_template 多场景配置:
bank_id_template 是实现记忆隔离的关键配置。它支持 profile、workspace、platform、user、session 五个模板变量:
# 场景 1:个人使用,所有记忆共享
bank_id_template: "my-agent"
# 场景 2:多用户隔离(客服场景)
bank_id_template: "user-{user}"
# user-alice 和 user-bob 的记忆完全隔离
# 场景 3:多工作区隔离(项目管理)
bank_id_template: "{workspace}"
# workspace-project-a 和 workspace-project-b 独立记忆
# 场景 4:按平台 + 用户隔离
bank_id_template: "{platform}-{user}"
# telegram-alice 和 discord-alice 可以有不同记忆
# 场景 5:会话级隔离(临时记忆)
bank_id_template: "{platform}-{user}-{session}"
# 每个会话独立记忆,适合一次性任务场景retain_every_n_turns 的权衡:
# 每轮都 retain(默认):记忆最完整,但 API 调用更频繁
retain_every_n_turns: 1
# 每 3 轮 retain:减少 API 开销,可能遗漏部分信息
retain_every_n_turns: 3
# 每 5 轮 retain:适合高频但低信息密度的对话
retain_every_n_turns: 5对于开发场景,建议保持 1(每轮 retain)。对于闲聊场景,3 或 5 就够了。
六、应用场景:从个人助理到企业级 Agent
看几个实际的应用场景。
个人开发助手
这是最直接的场景。Agent 记住你的项目技术栈、代码风格偏好、常用的依赖版本。每次对话不需要重复上下文。它还能通过 reflect 发现你的编码习惯模式,给出越来越精准的建议。
比如你在一个月内多次修改 ESLint 配置,Agent 会 reflect 出你可能对代码规范有持续调整的需求,主动提供相关建议。
项目管理 Agent
利用 Hindsight 的 reflect 操作,项目管理 Agent 能从历史交互中发现风险模式。比如"这个项目在过去三周的冲刺中,每次周二的任务完成率都偏低",然后主动提醒你调整计划。
Hermes 的闭环学习会将这种模式提炼为技能,未来遇到类似项目时自动应用。
客服系统
通过 bank_id_template: "user-{user}" 实现多用户记忆隔离。每个用户的投诉历史、偏好和已解决的问题都独立存储。Agent 能回忆起"这位用户上周反馈过相同的问题",提供连贯的服务体验。
同时,reflect 能发现文档未覆盖的共性问题,帮助优化知识库。
销售 Agent
销售场景最需要模式识别。Agent 通过 Hindsight 记住每位客户的沟通风格、响应时间模式和决策偏好。经过 reflect 分析后,Agent 能总结出"周四下午发送的消息回复率最高"这类洞察,帮助优化沟通策略。
七、总结与展望
Hindsight + Hermes-Agent 的组合解决了一个核心问题:让 AI Agent 从"记住对话"进化到"从经验中学习"。
这套方案的亮点在于三层互补设计:
- L1 内置记忆(MEMORY.md/USER.md)保证关键信息的即时访问
- L2 Hindsight 记忆(World/Experiences/Mental Models)提供无限扩展的深度记忆
- 闭环学习循环确保记忆能转化为可复用的技能和知识
当前方案仍有局限:reflect 操作依赖 LLM 质量,多 Agent 共享记忆还在探索阶段,Local Embedded 模式的性能上限受限于单机资源。
未来的发展方向包括:更强的自主反思能力、多 Agent 间的共享记忆池、更精细的记忆淘汰策略。这两个项目都在活跃开发中,社区生态也在快速成长。
如果你正在构建需要长期记忆的 AI Agent,现在就是最好的上手时机。5 分钟的配置,就是你的 Agent 从"健忘"到"博学"的起点。
参考资料
- Hindsight GitHub 仓库 — Vectorize.io 开源的 Agent 记忆引擎
- Hindsight 官方文档 — 包含 API 文档和部署指南
- Hindsight 论文 — 仿生记忆模型的理论基础
- Hermes-Agent GitHub 仓库 — NousResearch 的自进化 Agent 框架
- Hermes-Agent 官方文档 — 配置和使用指南
- AgentSkills.io — 开放的 Agent 技能标准和共享平台