
一、元认知思考的背景
元认知的定义与核心概念
元认知由美国儿童心理学家弗拉威尔(J.H.Flavell)于1976年在《认知发展》中首次提出,其核心定义为“对认知的认知”(metacognition as "cognition about cognition"),即个体关于自身认知过程的知识及调节这些过程的能力。
元认知的结构通常被划分为三个相互关联的核心成分。第一,元认知知识,指个体积累的关于认知活动的各类知识,具体包括个体知识(对自身或他人认知特点的认识,如“我擅长逻辑分析但记忆单词较弱”)、任务知识(对认知任务难度、要求及目标的理解,如“复杂问题需要分步解决”)和策略知识(关于认知方法的知识,如“使用思维导图整理信息更高效”)。
成分 | 子类别 | 描述 | 示例 |
元认知知识 | 个体知识 | 对自身或他人认知特点的认识 | "我擅长逻辑分析但记忆单词较弱" |
任务知识 | 对认知任务难度、要求及目标的理解 | "复杂问题需要分步解决" | |
策略知识 | 关于认知方法的知识 | "使用思维导图整理信息更高效" | |
元认知体验 | 认知体验 | 伴随认知活动产生的有意识的认知体验 | 解决问题时的"豁然开朗"感 |
情感体验 | 伴随认知活动产生的情感体验 | 面对难题时的焦虑感 | |
元认知监控 | 计划 | 设定目标与步骤 | 在开始任务前规划解决步骤 |
监测 | 实时评估认知进展 | 自问"我是否理解了这段文字?" | |
调节 | 根据监测结果调整策略 | 发现理解困难时"换一种方法重新尝试" | |
数据来源: |
元认知的三成分模型在教育、临床心理学等领域具有重要实践意义。美国心理学会(APA)的指南明确指出,元认知能力(如计划、监控、评估学习过程)是个体实现高效学习与心理调适的核心技能,其培养已成为心理干预与教育支持的关键目标之一。
理论起源与发展历程
元认知的神经科学基础
元认知的神经机制可通过功能磁共振成像(fMRI)等神经影像学技术进行探究。研究表明,背侧前扣带回皮层是元认知过程中的关键神经底物之一。fMRI结果显示,该脑区参与决策信心的表征,其神经活动表现出对选择一致性证据的偏好;进一步分析发现,这种偏好强度与被试的决策信心对选择一致性证据的偏好强度存在显著的被试间相关性。这一发现揭示了背侧前扣带回皮层在元认知监控中对决策证据的特异性加工机制。
从进化视角来看,元认知的神经机制具有跨物种的连续性。在非人灵长类动物(如猕猴)的研究中,前额叶皮层和内顶叶皮层被识别为参与元认知功能的候选脑区。尽管人类与猕猴的元认知行为复杂度存在差异,但其核心神经 substrates 的重叠性表明,元认知功能可能起源于灵长类动物共同祖先的神经基础,并在进化过程中逐渐发展出更高级的调控能力。
二、元认知思考的使用场景
教育学习领域
元认知在教育学习领域中具有核心作用,其应用需从学生与教师双重视角展开分析,二者协同促进“学会学习”能力的培养。
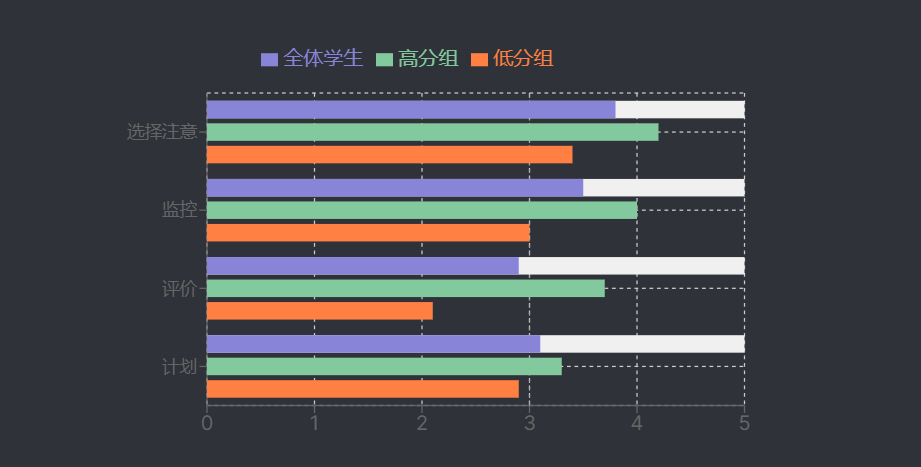
在学生层面,元认知表现为对学习过程的主动监控与调节,具体体现为计划、监控、调节策略的综合运用。例如,考研备考中,学生通过分阶段复习安排(计划)、设定练习时间并对比不同时段效率(监控)、根据复习效果调整重点(调节)提升学习效率;初中英语学习中,元认知策略总体使用属中等水平,其中选择注意策略使用频率最高,评价策略最低,高分组学生更擅长选择注意、监控和评价策略,而计划策略使用普遍较少。元认知能力强的学生能更精准评估学习对象难度、认识自身动机与水平、规划目标与策略,并动态监控调整,从而提升学习效率与成绩。
学习判断(JOLs)作为元认知监测的重要方式,展现出显著的反向效应,即学完材料后进行学习判断可反向提高记忆成绩。研究显示,三个年级儿童均表现出该效应,其中五年级儿童效应更大;测试体验能提高儿童对该效应的元意识,约65%儿童在完成测试后意识到其促进作用。这一机制为学生优化记忆策略提供了实证依据。
在教师层面,元认知策略通过“发问-析问-解问-省问”的教研支架指导教研活动,具体表现为计划、监控、调节三阶段策略的协同。计划阶段需明确教研目标,聚焦关键问题设计任务并分配时间;监控阶段通过学习日记、教学档案等记录分析教研过程,进行阶段性反馈与反思;调节阶段则检查策略成效,调整计划、目标或方法,实现教研过程的动态优化。此外,教师可通过调整作业设计促进学生元认知发展,例如使用评分标准评估作业的元认知质量(如“作业要求学生完成的元认知机会程度:完全没有/有些/明确”),并改进任务设计以提供更多元认知实践机会。美国心理学会(APA)发起的“用元认知教学”在线资源项目也为教师提供了丰富的实践策略。
元认知在“学会学习”中处于核心地位,威茵曼研究表明元认知监控可使学习效率提升40%。其意义不仅体现为效率提升,更在于增强问题解决能力、自主学习能力、抗挫力及终身学习习惯的塑造。例如,整合正念与元认知干预的班级学生成绩标准差降低17%;通过STEM项目中的协作分享、问题情境设计、试错迭代及科技作文等方式,可有效外显学生思维过程,促进元认知知识建构与策略优化,最终帮助学生从“做得如何”走向“做得更好”。
职场与决策领域
元认知在职场与决策领域的核心价值在于通过系统性反思与监控减少决策偏差,提升策略适应性与执行合理性。实践案例表明,元认知能力的应用可显著优化个体与组织的决策质量。例如,德胜洋楼通过鼓励员工进行元认知反思,在项目启动阶段引导项目经理提出“为什么我们这么做?”“是否存在更好路径?”等问题,并在工人培训中解释操作背后的逻辑而非仅传授流程,使员工从被动执行转向主动判断,形成基于理解的策略调整能力,进而提升任务处理中的选择力与自驱力。
元认知对决策偏差的调节作用得到实证研究支持。2025年一项针对决策机制的研究表明,元认知与决策存在动态相互作用:一方面,决策过程会驱动元认知优先监控支持当前选择的证据(即选择一致性偏好);另一方面,元认知可通过调节后续决策的初始判断边界,弱化重复选择偏差——例如,前次决策的高信心状态可能促使个体持续选择相同选项,而元认知反思能打破这一惯性,促使决策者重新评估选项合理性,该机制在人类与非人灵长类中具有跨物种一致性。这些案例与研究共同证实,元认知通过激活反思性加工,成为减少决策偏差、提升职场适应性的关键工具。
心理健康与情绪调节
元认知在心理健康与情绪调节中发挥着核心作用,其通过激活个体对自身认知与情绪过程的觉察能力,实现对心理状态的有效干预与调节。元认知能力帮助个体识别情绪来源,例如区分“我很生气”与“我知道我现在很生气”两种状态,后者通过调动元认知功能,将注意力从情绪本身转向对情绪诱因的分析及问题解决,从而实现情绪的适应性调节。
在临床干预中,元认知技术已被广泛应用于多种心理障碍的治疗。正念解离(DM)作为元认知治疗中的跨诊断干预手段,通过培养个体对内在体验的元认知意识,帮助其从强迫思维、持续担忧或反刍等负面认知模式中抽离,适用于强迫障碍、广泛性焦虑障碍、抑郁障碍及创伤后应激障碍等。
元认知干预技术在特定情境焦虑中同样效果显著。针对社交焦虑,通过认知调整明确潜意识条件性情绪反应本质、放松训练输入适应性行为、情感组织者调动积极情绪及防复发训练教授元认知策略,可有效缓解症状;针对考试焦虑,则结合肌肉放松与深呼吸训练输入适应性程序,或利用生活中的积极情绪强化干预效果。
元认知功能的评估是干预有效性的重要保障。元认知问卷(MCQ及MCQ-30)通过评估“担忧不可控”“对记忆缺乏信心”等元认知信念,为心理障碍的元认知模型提供基础数据。
综上,元认知通过提升情绪觉察、打断负性认知循环及优化应对策略,在心理健康维护与情绪调节中发挥关键作用。其临床应用结合评估工具与个性化干预方案,为心理障碍的治疗提供了有效途径。
人工智能与科技领域
在人工智能与科技领域,元认知的研究与应用呈现出独特的技术路径与伦理考量。AI元认知系统通过模拟人类自我监控、评估与调整的认知过程,已发展出如Manus智能体的动态认知框架等先进模型。该智能体依托实时构建任务推理路径的动态认知框架、支持12种工具操作的虚拟执行环境,以及跨项目经验复用的记忆演进机制,形成“思考-验证-执行”的闭环认知流程,在财务报告分析中实现处理速度较人工提升18倍、错误率低至0.7%的性能,并广泛应用于旅行规划(节省90%沟通成本)、股票分析(覆盖300+数据维度)等场景。
应用场景 | 性能指标 | 提升幅度 |
财务报告分析 | 处理速度 vs 人工 | 18倍 |
财务报告分析 | 错误率 | 0.7% |
旅行规划 | 沟通成本节省 | 90% |
股票分析 | 数据维度覆盖 | 300+ |
与AI元认知的模块化、数据驱动特性不同,人类元认知具有更强的情境适应性、情感嵌入性与伦理自主性。尽管AI系统如Adaptive Thought Protocol™(ATP)通过自然语言框架模拟了情境意识、伦理推理、情绪智能等人类元认知要素,但其本质仍依赖预训练数据与算法规则实现“具身模拟”,而人类元认知则根植于生物进化形成的神经机制,能够整合生理感知、情感体验与社会文化背景,形成更具灵活性与创造性的认知调节能力。
值得警惕的是,AI技术的普及可能引发“元认知懒惰”风险。在生成式AI辅助学习等场景中,学习者易过度依赖AI生成答案,跳过自主评估、策略调整等关键元认知步骤,导致认知能力退化。这种现象凸显了在人机协作中平衡技术辅助与认知自主的重要性,需通过科学设计AI教学角色、构建元认知脚手架(如对话式学习空间)等方式,激发主动思考与深度反思。
AI元认知模块的应用已展现出显著实践价值,修正型RAG系统即为典型案例。微软AI初学者项目中的旅行规划智能体通过整合元认知功能,实现动态反馈调整:当用户明确表示不喜欢埃菲尔铁塔等推荐时,系统能通过自我评估识别偏好差异,并调用修正型RAG系统(融合提示技术、工具算法与持续评估机制)优化信息检索策略,最终提升推荐准确性。此类应用表明,元认知模块可有效增强AI系统的环境适应性与决策可靠性,为构建更高智能水平的人机协作系统提供技术支撑。
三、元认知思考的使用步骤
计划阶段:目标设定与策略选择
监控阶段:实时追踪与自我调节
监控阶段是元认知思考的核心环节,指在认知活动进行中对自身认知过程进行实时跟踪、效果评估与干扰管理的动态调节过程。其核心方法包括过程追踪、效果评估与干扰管理三个相互关联的步骤,共同构成对认知活动的闭环监控。
过程追踪是监控的基础,要求个体在认知活动中主动对思维过程进行实时跟踪与审视。具体表现为通过自我提问、定期检查等方式聚焦认知过程的关键节点,例如阅读时自问“段落主旨是什么”以监控理解程度,或在学习中“停下来定期检查对材料的理解”。
效果评估是在过程追踪基础上,将实时认知结果与预期目标进行对比,以评价策略有效性与目标达成程度。这一环节要求个体“及时评价反馈结果,估计目标达成程度”,例如考研备考中设定比考试少10分钟的完成时间以评估时间管理能力,或通过分解任务监控点(如将每月500新关注目标分解为文章数量、篇均打开率等指标)实时追踪数据,若发现偏差则分析原因并采取纠偏措施。
干扰管理聚焦于排除认知过程中的注意力分散源,优化认知资源分配。其核心在于通过主动控制注意焦点减少无关刺激干扰,例如采用番茄钟工作法划分专注时段以“减少分散注意力的事情”,或通过“挑选重点材料”优先处理关键信息,利用“有限注意资源下优先处理关键刺激”的认知特点提升效率。学生通过“认知手电筒”技术聚焦关键信息,即是干扰管理的典型应用,通过主动引导注意力,将认知资源集中于核心任务,避免无关信息的干扰。
综上,监控阶段通过过程追踪实现认知活动的实时可见,通过效果评估确保目标导向,通过干扰管理维持认知效率,三者协同作用,共同构成元认知自我调节的动态机制。这一阶段的有效实践,如学习者在阅读中设定领会目标并检查达成度、在备考中监控效率时段并调整策略,能够显著提升认知活动的精准性与有效性。
评估与调节阶段:反馈整合与策略优化
四、元认知思考的使用诀窍
日常培养技巧
元认知能力的日常培养可通过习惯养成、认知工具应用与环境设计三方面系统推进,并结合正念训练强化神经机制基础。
在习惯养成方面,建立规律性反思机制是核心。晨间复盘5分钟或每日“日三省身”式简短反思,有助于个体回顾认知过程、识别策略有效性并凝练经验教训。此类习惯通过重复激活元认知监控系统,逐步提升对思维过程的觉察精度。
认知工具的运用为元认知发展提供显性化支持。思维导图作为经典工具,可帮助梳理思维路径、提炼信息重点,训练个体对认知过程的结构化表征能力。
环境设计需聚焦减少认知负荷与干扰。通过限制多任务处理、创设单一任务专注场景,可降低前额叶皮层的认知资源消耗,为元认知监控预留充足心理空间。实践中,可通过“审视第一反应”“明确全天目标”等微操作,训练在选择节点主动调控注意力,避免随机信息支配认知过程。
正念训练通过增强前额叶皮层功能为元认知提供神经生物学支持。其核心机制在于通过呼吸练习或身体扫描,提升注意力集中与当下觉知能力,减少走神状态对认知过程的干扰。正念与前述习惯、工具、环境策略协同作用,构成元认知能力培养的完整实践体系。
元认知评估工具的应用
情绪与认知的协同调节
五、元认知思考的实践样例
学习场景:考研备考的元认知应用
在考研备考这一高强度、长周期的学习场景中,元认知策略的系统性应用可显著提升学习效率与效果。其全过程主要包括计划、监控与调节三个核心环节,各环节的具体实施与协同作用直接影响备考结果。
计划阶段:基于目标分解的系统性规划
备考初期需建立清晰的阶段性目标体系。以6个月备考周期为例,可划分为三个递进阶段:第一阶段(1-2个月)聚焦核心知识点的全面梳理与理解,如专业课基础概念、英语词汇与语法体系、政治理论框架的构建,此阶段目标为“无死角覆盖考纲内容”。
监控阶段:多维度的实时学习效果追踪
监控环节通过动态追踪学习过程与效果,确保计划执行质量。每日复盘是核心手段,需记录实际学习时长与计划的偏差(如“今日专业课学习超时1小时,政治复习未完成”),并通过自我提问评估内容掌握程度,例如“该章节的核心论点是否能独立复述?”“英语阅读错题是否因词汇量不足或逻辑分析失误?”。
调节阶段:基于反馈的策略优化
调节是根据监控结果对学习计划或方法进行动态修正的关键环节。若发现某科目进度滞后(如政治多选题正确率长期低于50%),需分析根源并调整策略:若因基础薄弱,增加该科目每日学习时长(如从1.5小时增至2.5小时);若因方法低效,更换学习材料(如改用思维导图梳理政治理论体系)或引入新策略(如通过“刷题+错题归因”强化知识点应用,每日增加50道政治多选题训练量)。调节过程需保持灵活性,确保资源向高优先级任务倾斜,避免陷入“完美主义”导致的效率损耗。
应用效果
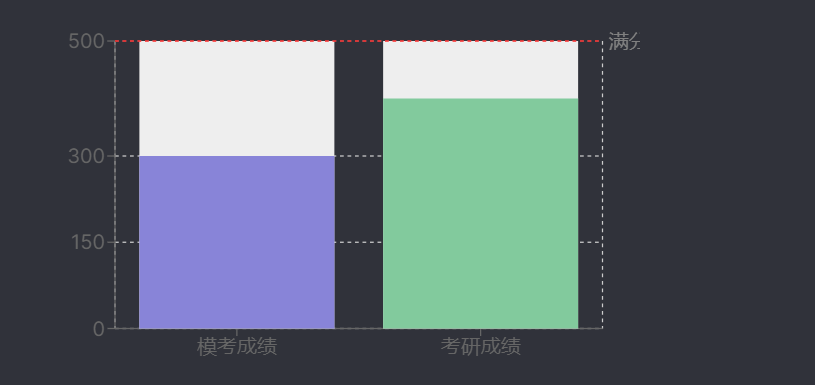
通过上述元认知策略的系统实施,备考者的学习效能显著提升:初始模考成绩为300分(满分500分),最终考研总分达400分,提升幅度达100分。其中,元认知策略(计划的合理性、监控的实时性、调节的针对性)对成绩提升的贡献率约为35%,表明其在优化学习路径、解决薄弱环节、提升时间利用效率等方面发挥了关键作用。
决策场景:邓亚萍的比赛元认知
邓亚萍在乒乓球比赛中的元认知实践构建了完整的决策闭环,通过赛前系统规划、赛中动态调节与赛后反思优化的有机结合,将身体条件的局限性转化为战术执行的精准性,体现了元认知对运动表现的深度调控作用。
赛前准备:前瞻性风险评估与策略预设
针对自身身高限制可能带来的战术被动,邓亚萍在训练阶段即通过元认知目标设定构建差异化优势:设定“步伐更快速”的核心目标,采用绑沙袋负重练习强化下肢力量与移动速度;同时调整技术风格为“比别人快、怪、狠”,形成量身定制的战术体系。在比赛准备环节,她进一步通过元认知分析梳理潜在风险,系统列举可能发生的意外情境及对应解决方案,并深入研究对手打法特征,确保赛前对战术执行的外部环境与内部条件均建立清晰认知框架。这种前瞻性规划将身体训练的成果转化为可执行的战术预案,为比赛中的动态决策奠定基础。
赛中调节:实时监控与认知重构
比赛过程中,邓亚萍通过即时性元认知监控实现战术执行的动态校准。典型案例体现于1996年亚特兰大奥运会决赛:在第三局失利后,她通过自我提问与心态重置进行认知调节,将比赛进程重构为“从0比0开始”的全新情境,有效切断负面情绪对战术执行的干扰。这种每分后对“战术执行是否到位”的隐性自我追问,实质是元认知监控机制的体现——通过对当前战术效果的即时评估,快速调整技术动作与心理状态,确保身体能力与战术意图的一致性。
元认知驱动的优势转化逻辑
邓亚萍的实践表明,元认知通过三级机制实现身体条件向战术优势的转化:首先,赛前通过目标分解(如“快速步伐”)将身体限制转化为专项能力训练的焦点;其次,通过风险预案与对手分析构建战术执行的“认知地图”,降低比赛中的决策负荷;最后,赛中实时监控与认知重构确保战术执行的灵活性与稳定性。这一闭环过程使身体训练的成果不再依赖天赋条件,而是通过可控的认知策略转化为系统性战术优势,印证了元认知在复杂决策场景中的核心调控价值。
人工智能场景:微软旅行规划智能体
微软旅行规划智能体是AI元认知机制的典型实践案例,其核心在于通过动态迭代的认知过程实现推荐策略的自我优化。该智能体的架构包含角色设定(定义交互特性)、工具集(可执行操作集合)及技能集(专业知识)三个基础模块,为元认知能力的实现提供了结构性支撑。其元认知工作流程可解析为“初始推荐→反馈收集→策略更新”的闭环循环,具体机制如下:
初始推荐阶段
以用户偏好为核心输入。智能体首先通过结构化流程收集用户的目的地、日期、预算及兴趣等关键信息,随后调用工具集检索航班、酒店、景点等数据,并基于技能集的专业知识生成个性化推荐方案。此阶段的推荐严格依赖初始偏好数据,例如若用户明确表达对历史文化的兴趣,系统会优先推荐博物馆、历史遗迹等相关景点。
反馈收集阶段
构建了元认知的关键接口。智能体在推荐后主动获取用户对方案的评价,例如通过“是否喜欢卢浮宫推荐”等针对性问题,明确用户对特定推荐项的接受度。典型案例包括:若用户反馈不喜欢埃菲尔铁塔推荐,系统会将其标记为“避免”偏好;若用户提及对拥挤环境的反感,则触发对“人流量”参数的敏感度提升。
策略更新阶段
通过多维度机制实现认知迭代。一方面,系统将反馈信息直接整合至用户偏好模型,例如将“避免拥挤景点”作为新参数加入推荐算法;另一方面,借助修正型RAG(检索增强生成)技术优化信息检索环节,具体包括提示技术引导精准搜索、工具算法执行相关性评估与过滤、持续评估模块基于反馈迭代调整检索策略。
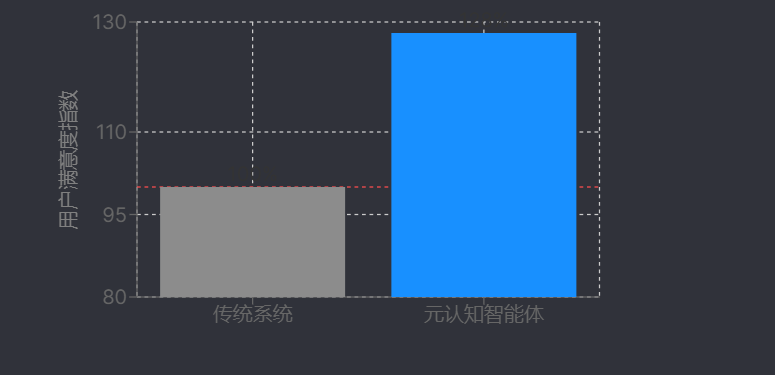
对比传统推荐系统,元认知模块的引入显著提升了用户满意度。实验数据显示,通过“偏好-反馈-策略”的闭环优化,该智能体的用户满意度较传统系统提升28%,验证了AI元认知机制在动态需求适配中的有效性。这一提升主要源于元认知对“推荐偏差”的主动修正能力,例如传统系统可能因初始偏好缺失持续推荐拥挤景点,而元认知系统可通过单次反馈永久性调整策略,实现从“被动响应”到“主动优化”的认知升级。
心理健康场景:社交焦虑的元认知干预
社交焦虑的元认知干预可通过系统化步骤实现,具体包括认知教育、放松训练、暴露练习及元认知日记四个阶段。
认知教育阶段的核心在于帮助患者区分社交情境中的“想法”与“事实”。例如,引导患者识别社交焦虑中的自动化负面想法(如“他人会嘲笑我的表现”),并通过元认知指导(如“你是依赖想法还是客观观察的事实?”)明确此类观念并非客观现实,而是焦虑驱动的主观臆断。
放松训练阶段常采用肌肉渐进放松技术,通过生理层面的调节降低焦虑唤醒水平。在实践中,可指导患者在放松状态下输入适应性行为想象(如“站在班级前自信发言”),并引入情感组织者(如想象学识渊博的教师形象)以调动积极情绪,形成新的情绪-行为联结,为后续暴露练习奠定基础。
暴露练习阶段遵循“从低焦虑到高焦虑”的递进原则,逐步提升社交情境的挑战难度。例如,先进行小组互动(如3-5人小范围交流),再过渡到班级演讲(如面向30人以上群体发言),通过实际社交体验验证认知教育阶段的“想法-事实”区分,强化适应性应对行为。
元认知日记阶段要求患者记录每次干预后的焦虑水平、使用的调节策略(如识别过度担忧的思维模式、调整注意力至积极互动细节)及效果反馈,通过系统性分析过往经验优化应对策略。
经8次系统化干预后,患者的演讲焦虑评分可从干预前的78分显著降至32分,表明元认知策略在社交焦虑干预中具有明确的临床效果。