
生活化例子
- 数据预处理 - 就像烹饪前要洗菜切菜,数据需要清洗和整理才能使用
- 模型训练与评估 - 类似教孩子认动物:先看带标签的图册(训练),再测试新图片识别能力(测试)
- 过拟合与欠拟合 - 像考试作弊(死记硬背训练题)和没复习(完全不会新题)的极端情况
概念讲解
- 监督学习(材料3[3])
- 使用带标签的数据训练模型,就像老师批改作业时会告诉学生正确答案。常见应用:房价预测、垃圾邮件分类
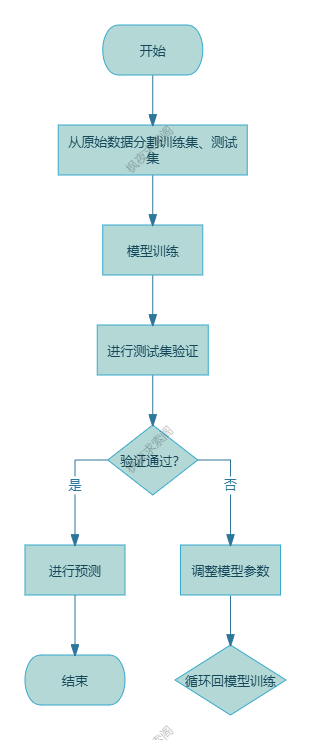
- 数据划分(材料1[1])
- 通过
train_test_split将数据分为训练集(教材)和测试集(模拟考卷),防止模型作弊。典型划分比例是7:3或8:2
- 模型泛化能力(材料4[4])
- 模型处理新数据的能力,好比学生在真实考场中的发挥水平。评估指标包括准确率、召回率等
- 特征工程(材料5[5])
- 将原始数据转化为有效特征的过程,类似把食材加工成适合烹饪的形态。例如将日期分解为星期、季节等特征
- 正则化(材料4[4])
- 防止模型过拟合的技术,相当于给模型戴"紧箍咒"。常用方法包括L1正则化(特征筛选)和L2正则化(权重限制)
简单记法
- 数据三部曲:分(分割数据)→ 训(训练模型)→ 测(测试评估)(对应材料1代码结构)
- 学习类型口诀:"监工无家可归" → 监督学习、工程应用、无监督学习、强化学习、生成式AI(材料3[3])
- 过拟合识别:训练高分测试低,模型可能背题库(材料4[4])
图示
参考资料
2.【机器学习】机器学习的基本知识点(包括背景、定义、具体内容、功能、使用场景、操作、未来发展和常见算法)-csdn博客
3.什么是机器学习? | Machine Learning | Google for Developers