
1. 引言
在人工智能领域,深度学习模型的发展日新月异,而Transformer架构无疑是最具革命性的突破之一。自2017年Vaswani等人在论文《Attention Is All You Need》中首次提出Transformer模型以来,这一架构彻底改变了自然语言处理(NLP)领域的范式,推动了BERT、GPT等系列模型的诞生和广泛应用。本篇文章将深入探讨Hugging Face开源的Transformers库,详细剖析其历史背景、技术原理和使用方法,帮助读者全面了解这一前沿技术。
2. Transformer模型的历史发展
2.1. 背景与挑战
在Transformer出现之前,循环神经网络(RNN)及其更先进的版本,如长短时记忆网络(LSTM)和门控循环单元(GRU),是处理序列任务的主流架构,例如机器翻译和文本生成。这些模型逐步处理序列,本质上是序列化的,这限制了它们的并行化能力。此外,传统的序列模型在捕获远程依赖性和实现并行计算方面存在局限性。
2.2. 注意力机制的引入
注意力机制最初被提出来用于改善序列到序列的任务,它使模型在产生输出时能够关注输入数据的不同部分。本质上,它使网络能够根据它们的重要性"关注"输入的不同部分。
2.3. Transformer模型的诞生(2017)
Transformer架构首次在2017年的开创性论文《Attention Is All You Need》中由Vaswani等人提出。它完全放弃了循环层,仅依赖于注意力机制,特别是一种名为"多头自注意力"的新型变体。这使得Transformer高度并行化,导致了训练速度的提升。该论文还引入了位置编码的概念,这使模型可以考虑序列中单词的位置,因为架构本身是排列不变的。
Transformer模型的提出正是为了解决这些问题,其核心理念是用自注意力机制(Self-Attention)替代RNN结构,从而提高模型的并行性和处理长序列依赖的能力。
2.4. BERT和其变体(2018年及以后)
2018年,Google推出了BERT(Bidirectional Encoder Representations from Transformers),将Transformer架构提升到了一个新的水平。BERT革命性地通过在大型语料库上预训练一个大型Transformer模型,然后在特定任务上进行微调。在BERT之后,提出了许多基于Transformer架构的变体和模型,如GPT (Generative Pre-trained Transformer)系列。
3. Transformer模型的架构详解
3.1. Transformer的基本结构
Transformer模型由两个主要组件组成:编码器和解码器。编码器接收输入文本,并生成一系列隐藏状态,这些隐藏状态表示文本的含义。然后,解码器接收编码器的隐藏状态,并逐字生成输出文本。
Transformer的核心机制之一——多头自注意力(Multi-Head Attention)为处理序列数据提供了前所未有的灵活性和表达能力。
3.2. 自注意力机制
自注意力机制的核心思想是,序列中每个元素都与其他所有元素相关,并且这种关系是通过注意力权重来表示的。自注意力机制可以捕捉序列内部的长距离依赖关系[。
在注意力机制中,Q(Query)、K(Key)和V(Value)通过映射矩阵得到相应的向量,通过计算Q与K的点积相似度并经过softmax归一化得到权重,最后使用这些权重对V进行加权求和得到输出。
3.3. 多头自注意力机制
多头自注意力是自注意力机制的扩展,它将输入分割成多个"头",每个头学习输入的不同部分表示,然后将这些表示合并起来,以捕获信息的不同方面。
多头自注意力机制(Multi-Head Attention)是Transformer模型中的一个核心组件,它使得模型能够在处理序列数据时,同时关注序列的不同部分,从而捕捉序列内部的复杂关系。
具体来说,多头自注意力机制将输入序列映射到多个不同的表示空间中,然后分别计算这些表示之间的注意力权重。这样做的好处是,模型可以学习到序列中不同子空间下的信息,比如一个头可能专注于捕捉局部的语法结构,而另一个头可能专注于理解更广泛的语义信息。
3.4. 位置编码
位置编码是Transformer架构中的一个重要组成部分,它为模型提供关于输入中每个元素位置的信息。由于Transformer本身不具备处理序列顺序的能力,通过添加位置编码到输入序列,模型能够利用序列中元素的位置信息。
位置编码实际上是一个向量,把它跟词向量结合,放在词向量中。位置编码可以有多种实现方式,Transformer原始论文中提出的位置编码是通过正弦和余弦函数来计算的,这样做的好处是能够让模型学习到相对位置信息,因为这些函数对位置的偏移是可预测的。
3.5. 编码器和解码器
Transformer的编码器和解码器都由多个相同的层堆叠而成。每个编码器层包含两个子层:多头自注意力机制和前馈神经网络。每个解码器层包含三个子层:自注意力、编码器-解码器注意力和前馈神经网络。
编码器接收输入文本,通过多层处理生成一系列隐藏状态,这些隐藏状态表示文本的含义。解码器接收编码器的隐藏状态,并通过多层处理逐字生成输出文本。
3.6. 残差连接和层归一化
残差连接和层归一化是Transformer架构中的两个重要组件,它们有助于提高模型的训练效率和性能。
残差连接允许梯度直接从前面的层流向后面的层,这有助于缓解梯度消失或爆炸的问题。层归一化对每个样本的激活进行归一化,这有助于稳定训练过程,加快收敛速度。
4. Hugging Face Transformers库简介
4.1. 库的概述
Hugging Face的Transformers库是一个非常强大的工具,它提供了大量预训练模型,可以用于各种自然语言处理任务,包括但不限于分类(如文本分类、情感分析)、生成(如文本生成)、理解(如问答、摘要)、转换(如翻译)等。
Transformers是一个预训练模型库,涵盖自然语言处理、计算机视觉、音频和多模态模型,适用于推理和训练。使用Transformers可以在你的数据上训练模型,构建推理应用程序,以及使用大型语言模型生成文本。
Hugging Face的核心库是Transformers,这个库集成了各种预训练模型、分词器和相应的工具。通过这个库,用户可以方便地加载和使用这些模型,进行文本分类、命名实体识别、情感分析等任务
4.2. 主要功能
Transformers提供了进行推理或使用最先进的预训练模型进行训练所需的一切。一些主要功能包括:
- Pipeline:用于许多机器学习任务的简单和优化的推理类,如文本生成、图像分割、自动语音识别、文档问答等
- Trainer:一个全面的训练器,支持混合精度、torch.compile和FlashAttention等功能,用于训练和分布式训练PyTorch模型。
- generate:使用大型语言模型(LLMs)和视觉语言模型(VLMs)进行快速文本生成,包括对流式传输和多种解码策略的支持。
4.3. 设计原则
Transformers的设计原则是:
- 快速且易于使用:每个模型都只从三个主要类(配置、模型和预处理器)实现,可以快速使用Pipeline或Trainer进行推理或训练。
- 预训练模型:通过使用预训练模型而不是训练全新的模型,减少碳足迹、计算成本和时间。每个预训练模型都尽可能接近原始模型地重现,并提供最先进的性能。
5. Hugging Face Transformers库的使用方法
5.1. 安装和环境配置
使用Hugging Face的Transformers库之前,需要先安装必要的库和工具。确保你的环境中已经安装了Python和pip。接下来,安装Hugging Face的Transformers库和其他相关库。
pip install transformers datasets torch5.2. 加载预训练模型
可以通过模型的名称来加载预训练模型。以下是如何加载一个与BERT模型匹配的分词器:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')5.3. 使用分词器和模型
在进行自然语言处理任务时,可以使用分词器和模型对文本进行处理。例如,以下是如何使用BERT模型和分词器进行文本处理:
from transformers import BertTokenizer, BertModel
# 加载分词器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 对文本进行编码
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
# 通过模型进行前向传播
outputs = model(**inputs)5.4. 使用Pipeline进行推理
Pipeline是Transformers库中非常便捷的工具,可以用于多种NLP任务,如情感分析、文本分类、命名实体识别等。它会自动处理模型下载、分词和结果后处理。
以下是如何使用Pipeline进行情感分析:
from transformers import pipeline
# 创建情感分析Pipeline
classifier = pipeline("sentiment-analysis")
# 进行情感分析
result = classifier("We are very happy to show you the Transformers library.")
print(result)5.5. 使用Trainer进行训练
Trainer是Transformers库中提供的高级API,用于简化模型训练流程。它支持多GPU和TPU训练,以及各种训练参数配置。
以下是如何使用Trainer对BERT模型进行训练:
from transformers import Trainer, TrainingArguments
from datasets import load_dataset
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 加载数据集
raw_datasets = load_dataset("glue", "mrpc")
# 准备训练和验证数据集
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]
# 初始化模型和分词器
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./mrpc",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=3,
weight_decay=0.01,
)
# 创建Trainer实例
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
# 开始训练
trainer.train()5.6. 使用Pipeline进行文本生成
Hugging Face的Transformers库提供了用于文本生成的强大工具。以下是如何使用预训练的文本生成模型(如GPT-2)进行文本生成:
from transformers import pipeline
# 加载预训练的文本生成模型
generator = pipeline("text-generation", model="gpt2")
# 生成文本
result = generator("The future of AI is", max_length=50, num_return_sequences=5)
print(result)5.7. 使用Pipeline进行自动语音识别
Pipeline不仅可以用于文本处理任务,还可以用于自动语音识别等任务。以下是如何使用Pipeline进行自动语音识别:
import torch
from transformers import pipeline
# 加载自动语音识别Pipeline
speech_recognizer = pipeline("automatic-speech-recognition")
# 进行自动语音识别
result = speech_recognizer("path/to/audio/file.wav")
print(result)6. 常见模型示例
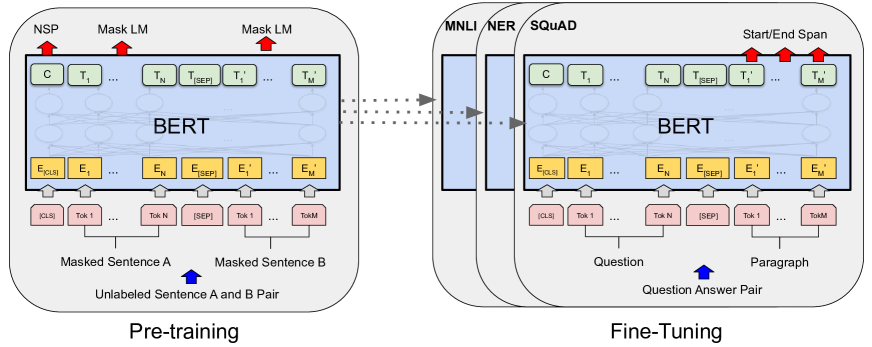
6.1. BERT模型
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年推出的预训练模型,它将Transformer架构提升到了一个新的水平。BERT通过在大型语料库上预训练一个大型Transformer模型,然后在特定任务上进行微调。
BERT的整体预训练和微调过程如下:
以下是如何使用Transformers库对BERT模型进行微调进行文本分类的代码示例:
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
Trainer,
TrainingArguments,
)
import datasets
# 加载数据集
dataset = datasets.load_dataset("imdb")
# 加载BERT模型和分词器
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./bert-imdb",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
# 定义数据处理函数
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length")
# 处理数据集
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 创建Trainer实例
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
)
# 开始训练
trainer.train()6.2. GPT模型
GPT(Generative Pre-trained Transformer)是由OpenAI开发的预训练模型,主要用于文本生成任务。GPT模型基于Transformer的解码器架构,通过在大量文本数据上预训练,学习生成自然语言文本的能力。
以下是如何使用Transformers库进行文本生成的代码示例:
from transformers import pipeline
# 加载预训练的GPT-2模型
generator = pipeline("text-generation", model="gpt2")
# 生成文本
result = generator(
"The future of AI is",
max_length=50,
num_return_sequences=5,
temperature=0.7,
top_p=0.9,
)
# 打印生成结果
for i, res in enumerate(result):
print(f"Generated sequence {i+1}:")
print(res["generated_text"])
print()6.3. MarianMT模型
MarianMT(Marian Machine Translation)是一个由MarianNMT团队训练的多语言翻译模型,支持多种语言对。以下是如何使用Transformers库进行机器翻译的代码示例:
from transformers import MarianMTModel, MarianTokenizer
# 指定模型名称
model_name = "Helsinki-NLP/opus-mt-en-de" # 英文到德文的翻译模型
# 加载模型和分词器
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
# 定义要翻译的文本
src_texts = ["Hello, how are you?", "This is a machine translation example."]
# 进行翻译
translated = tokenizer(src_texts, return_tensors="pt", padding=True)
outputs = model.generate(**translated)
translated_texts = [tokenizer.decode(t, skip_special_tokens=True) for t in outputs]
# 打印翻译结果
for i, (src, tgt) in enumerate(zip(src_texts, translated_texts)):
print(f"Source: {src}")
print(f"Translation: {tgt}")
print()7. Hugging Face Transformers库的优势与局限性
7.1. 优势
- 丰富的预训练模型:Hugging Face的Transformers库提供了数千个预训练模型,涵盖了自然语言处理、计算机视觉、音频和多模态等多个领域,大大减少了训练新模型的时间和计算成本。
- 简化的使用和微调流程:Transformers库提供了简单易用的API,如Pipeline和Trainer,使得用户可以快速加载和使用预训练模型,并轻松地对模型进行微调,以适应特定的任务。
- 多语言支持:Hugging Face的Transformers库支持多种语言的模型,推动了多语言NLP研究和应用。
- 社区协作:通过开源和社区驱动的方式,Hugging Face促进了知识共享和技术进步。
7.2. 局限性
- 计算资源需求:虽然使用预训练模型可以减少训练新模型的时间和计算成本,但对大型模型进行微调仍然需要大量的计算资源。
- 内存占用:大型预训练模型可能会占用大量的内存,这可能会限制在资源有限的环境中使用这些模型。
- 模型解释性:虽然Transformer模型在许多任务上表现出色,但它们的决策过程往往是黑盒的,缺乏透明度,这在某些需要高解释性的领域可能是一个问题。
8. 总结
Hugging Face的Transformers库是自然语言处理和人工智能领域的一个重要工具,它提供了大量预训练模型和简单易用的API,使得用户可以快速加载和使用这些模型,并轻松地对模型进行微调,以适应特定的任务。
从2017年Transformer模型的提出,到2018年BERT模型的推出,再到GPT系列模型的发展,Transformer架构已经彻底改变了自然语言处理领域,并在机器翻译、文本生成、问答系统等众多任务中取得了最先进的性能。
通过使用Hugging Face的Transformers库,开发者可以轻松地访问和使用这些最先进的模型,从而加速他们的研究和应用开发。无论是初学者还是经验丰富的研究人员,都可以从这个库中受益,快速实现他们的想法并将其转化为现实。
随着人工智能技术的不断发展,我们可以期待看到更多创新的模型和应用,而Hugging Face的Transformers库将继续在这个过程中发挥重要作用,为社区提供强大的工具和资源。
9. 参考资料
- 一文读懂 Transformer 神经网络模型_transformer神经网络-CSDN博客. https://blog.csdn.net/2401_84494441/article/details/139776225.
- 腾讯混元、英伟达都发混合架构模型,Mamba-Transformer要崛起吗?. https://new.qq.com/rain/a/20250324A04NM800.
- 详解:Hugging Face的transformers库_hugging face transformers 加训-CSDN博客. https://blog.csdn.net/qq_45058947/article/details/132032423.
- AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍_huggingface transformer库-CSDN博客. https://blog.csdn.net/HUANGXIN9898/article/details/143399787.
- Hugging Face 介绍_大模型应用落地架构实战-CSDN专栏. https://cloud.tencent.com/developer/article/2486580.
- 深入解析Transformer中的多头自注意力机制:原理与实现_1.请解释transformer中自注意力机制的工作原理,并说明为什么它能够更好地捕捉长距-CSDN博客. https://blog.csdn.net/2401_85743969/article/details/140196206.
- Transformer基础 多头自注意力机制-CSDN博客. https://blog.csdn.net/2401_86807530/article/details/145519740.
- 一文揭秘!Transformer的多头自注意力机制详解-CSDN博客. https://blog.csdn.net/bagell/article/details/144557277.
- 【Attention Is All You Need】Transformer模型精读_cross-attention is all you need: adapting pretrain-CSDN博客. https://blog.csdn.net/Lewiz_124/article/details/141940044.
- 1.1.1、transformer模型的历史_知乎. https://zhuanlan.zhihu.com/p/10035119962.
Transformers. https://huggingface.co/docs/transformers/index. - Transformer动画讲解 - 注意力计算Q、K、V-CSDN博客. https://blog.csdn.net/m0_59235245/article/details/139534637.
- Transformer结构及其应用详解--GPT、BERT、MT-DNN、GPT-2 - 知乎. https://zhuanlan.zhihu.com/p/69290203.
- 【大模型理论篇】Transformer原理及关键模块深入浅出_transformer模型-CSDN博客. https://blog.csdn.net/weixin_65514978/article/details/140954252.
- 【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客. https://blog.csdn.net/weixin_42475060/article/details/121101749.
- 【论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding】https://ar5iv.labs.arxiv.org/html/1810.04805?_immersive_translate_auto_translate=1
- 【论文:Improving Language Understanding by Generative Pre-Training】https://www.mikecaptain.com/resources/pdf/GPT-1.pdf