
1. 前言
在人工智能技术加速向多模态融合发展的今天,阿里通义千问团队推出的Qwen2.5-Omni,标志着多模态大模型从“单一感知”向“类人综合认知”的跨越式演进。作为全球首个端到端开源全模态大模型,Qwen2.5-Omni不仅支持文本、图像、音频、视频的实时交互与流式响应,更以7B超小参数量实现超越千亿级闭源模型的性能,在权威评测中全维度领先Google Gemini-1.5-Pro等竞品。
2. 关键特性
- 全能且新颖的架构:团队提出了 Thinker-Talker 架构,这是一个端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式方式生成文本和自然语音响应。我们提出了一个名为 TMRoPE(时间对齐多模态 RoPE)的新颖位置嵌入,用于同步视频输入的音频时间戳。
- 实时语音和视频聊天:专为完全实时交互设计的架构,支持分块输入和即时输出。
- 自然且鲁棒的语音生成:超越许多现有的流式和非流式替代方案,展示了在语音生成方面的优越鲁棒性和自然性。
- 模态间表现强劲:在与类似规模的单一模态模型进行基准测试时,Qwen2.5-Omni 在所有模态上表现出色。在音频能力方面,Qwen2.5-Omni 优于同样规模的 Qwen2-Audio,并在性能上与 Qwen2.5-VL-7B 相当。
- 优秀的端到端语音指令跟随:Qwen2.5-Omni 在端到端语音指令跟随方面的表现与文本输入相当,这由 MMLU 和 GSM8K 等基准测试所证明。
3. 性能评估
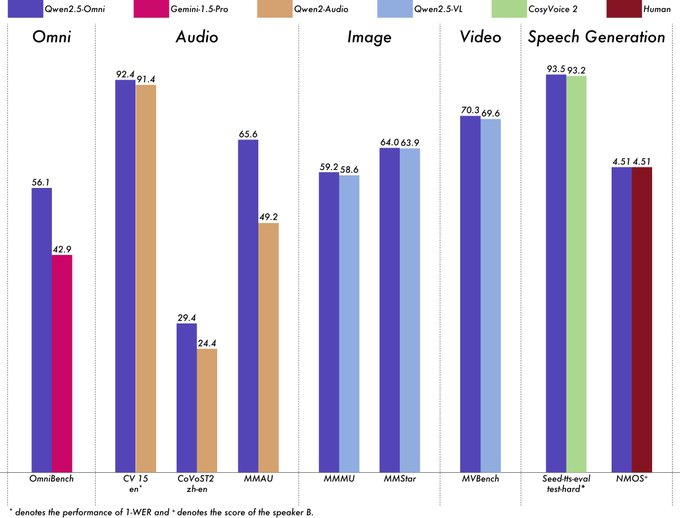
阿里团队对 Qwen2.5-Omni 进行了全面评估,与同等规模的单一模态模型和闭源模型(如 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro)相比,在所有模态上表现出强大的性能。在需要集成多个模态的任务中,如 OmniBench,Qwen2.5-Omni 实现了最先进的性能。此外,在单一模态任务中,它在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)和语音生成(Seed-tts-eval 和主观自然度)等领域表现出色。
4. 架构
Qwen2.5-Omni 采用 Thinker-Talker 架构。Thinker 功能类似于大脑,负责处理和理解来自文本、音频和视频模态的输入,生成高级表示和相应的文本。Talker 像人的嘴巴一样运作,以流式方式接收 Thinker 产生的高级表示和文本,并流畅地输出离散的语音标记。Thinker 是一个 Transformer 解码器,配有音频和图像编码器,以促进信息提取。相比之下,Talker 设计为双通道自回归 Transformer 解码器架构。在训练和推理过程中,Talker 直接从 Thinker 接收高维表示,并共享 Thinker 的所有历史上下文信息。因此,整个架构作为一个统一的单一模型运行,实现端到端训练和推理。架构图如下:

5. 快速入门
5.1. 安装
提供简单示例以展示如何使用 Qwen2.5-Omni 与🤗 Transformers。Qwen2.5-Omni 在 Hugging Face Transformers 上的代码处于拉取请求阶段,尚未合并到主分支。因此,您可能需要从源代码构建才能使用,构建命令为:
pip uninstall transformers
pip install git+https://github.com/huggingface/transformers@3a1ead0aabed473eafe527915eea8c197d424356
pip install accelerate
# It's highly recommended to use `[decord]` feature for faster video loading.
pip install qwen-omni-utils[decord]5.2. 使用样例
这里展示了一个代码片段,向您展示如何使用聊天模型与 transformers 和 qwen_omni_utils :
import soundfile as sf
from modelscope import Qwen2_5OmniModel, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# default: Load the model on the available device(s)
model = Qwen2_5OmniModel.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = Qwen2_5OmniModel.from_pretrained(
# "Qwen/Qwen2.5-Omni-7B",
# torch_dtype="auto",
# device_map="auto",
# attn_implementation="flash_attention_2",
# )
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
conversation = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=True)
inputs = processor(text=text, audios=audios, images=images, videos=videos, return_tensors="pt", padding=True)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)6. 相关资料
Qwen Chat: https://chat.qwenlm.ai
论文: https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
博客:https://qwenlm.github.io/blog/qwen2.5-omni/
GitHub: https://github.com/QwenLM/Qwen2.5-Omni
Hugging Face: https://github.com/QwenLM/Qwen2.5-Omni
ModelScope: https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B